
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- POD
- deep_learning
- Semiconductor
- flash_memory
- stl
- DRAM
- jhDNN
- cloud
- HA
- 양자역학의공준
- quantum_computing
- convolution
- FPGA
- 반도체
- kubernetes
- jhVM
- 쿠버네티스
- 반도체기초
- C++
- nvidia
- SpMM
- GPU
- 클라우드
- CuDNN
- 딥러닝
- CUDA
- dnn
- sycl
- Compression
- Qubit
- Today
- Total
Computing
Pod 네트워크 (2) : Service 내부 구현 분석 (kube-proxy와 iptables) 본문
Pod 네트워크 (2) : Service 내부 구현 분석 (kube-proxy와 iptables)
jhson989 2022. 12. 16. 22:55이전글
- Pod 네트워크 (1) : Service 필요성과 개념, 종류 (ClusterIP, NodePort, LoadBalancer)
이전 글에서 쿠버네티스의 서비스 리소스의 필요성과 그 개념에 대하여 정리하였다. 쿠버네티스 서비스는 파드들에 네트워크 접근할 수 있도록 변하지 않는 Private or Public IP를 제공하는 리소스이다. 사실 서비스 없이도 파드와 네트워크 통신할 수 있지만, 그 과정이 복잡하고 구현하기 까다롭다. (Iptables rule, routing table 설정 등을 Pod 정보가 변할 때마다 개발자가 직접 계속해서 관리해줘야 할 것이다.)
쿠버네티스는 서비스라는 추상화된 개념을 도입하여 이를 누구나 쉽게 이용할 수 있도록 제공한다. Fig 1.은 Service 개념을 잘 나타낸 그림으로 어떤 Client로 부터 같은 기능을 하는 Homogenous 파드 집합에 대한 네트워크 통신을 쉽게 해준다. Client가 Private or Public IP가 부여된 서비스와 통신하면, 내부적으로 서비스가 알아서 파드들에게 트래픽을 전달해준다. 이때 Client는 클러스터 내부 파드가 될 수도 혹은 외부 다른 애플리케이션, 사용자가 될 수 있다.

이번 포스터에서는 쿠버네티스에서 어떻게 서비스를 내부적으로 구현하였는 지에 대하여 정리하고자 한다. [쿠버네티스 인 액션], [1], [2] 자료를 참고하여 정리하였다.
Service 구현: iptables & kube-proxy
서비스를 구현하는 데 무슨 정보가 필요한 지를 생각해보자. Fig 2. Client pod와 Server pod와의 통신 예시를 나타낸 그림이다. Fig 2.의 상황에는 2개의 Nodes가 있고, 그 위에 2개의 Server pods와 1개의 Client pod가 실행되고 있다. 2개의 Nodes는 하나의 gateway에 연결되어 있다. 이 상황에서 Server pod들을 대표하는 서비스가 있으며, 그 서비스의 ClusterIP가 10.3.241.152라고 하자. Client pod는 이 서비스를 통해 Server pod에 접근하고자 한다.
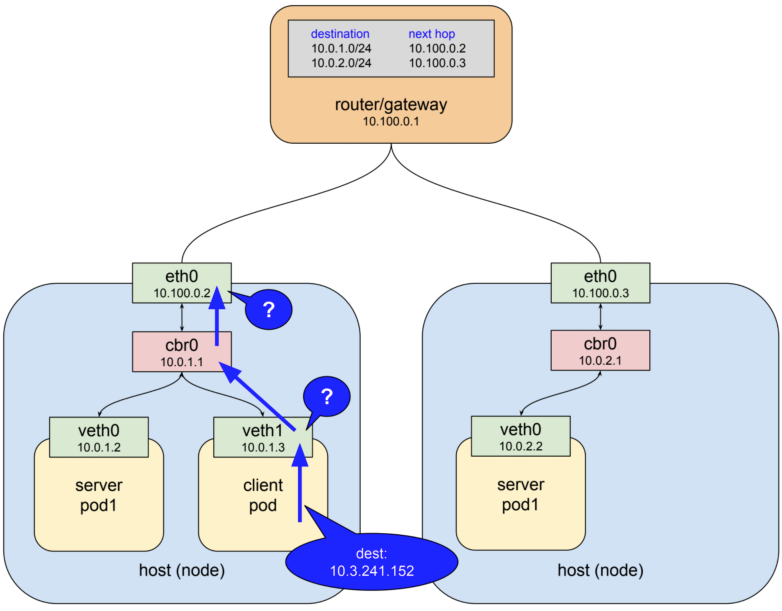
Client pod는 서비스의 주소 10.3.241.152에 접근을 시도할 것이다. 하지만 10.3.241.152 주소는 가상 IP이기에(ClusterIP는 모두 가상 IP), 파드의 veth1, 노드의 eth0 모두 어디로 트래픽을 보내야 할 지 판단할 수 없다. 라우팅 시 어디로 보내야 하는 지를 모르면 상위 네트워크로 보내기에 gateway로 트래픽이 전달될 것이다. 하지만 gateway 또한 10.3.241.152 주소를 모르기에(routing table에 없음) 결국 서비스로 향하는 트래픽은 성공적으로 전달되지 못한다.
이처럼 단순히 서비스만 등록하면 자연스럽게 알아서 서비스의 주소를 이용한 통신이 가능해지지 않는다. 노드들에게 그 서비스로 향하는 트래픽이 최종적으로 어떤 파드로 향해야 하는 지를 누군가가 알려주어야 한다. 쿠버네티스는 그 역할을 자동으로 수행할 kube-proxy를 제공한다. kube-proxy는 모든 노드에 하나씩 실행되는 daemonset으로, 각각이 실행되는 노드에게 서비스의 IP로 향하는 데이터를 어떤 Pod로 보내야 할 지를 알려준다.
kube-proxy는 userspace 모드, iptables 모드, IPVS 모드가 있는데 가장 많이 사용되는 iptables 모드로 설명하고자 한다. kube-proxy는 Fig 3.과 같이 iptables라고 하는 도구를 사용하여 노드들에게 들어오는 데이터를 조작한다. iptables[3]는 리눅스 패킷 필터링 도구로서 NAT(Network Address Translation)에 사용될 수 있다. 쉽게 말하자면 들어오거나 나가는 패킷(데이터)을 검사하여 원하는 주소로 보낼 수 있다. iptables은 rule 기반으로 작동하며, rule에 따라 A 위치로 가는 패킷을 B 위치로 보낸다.
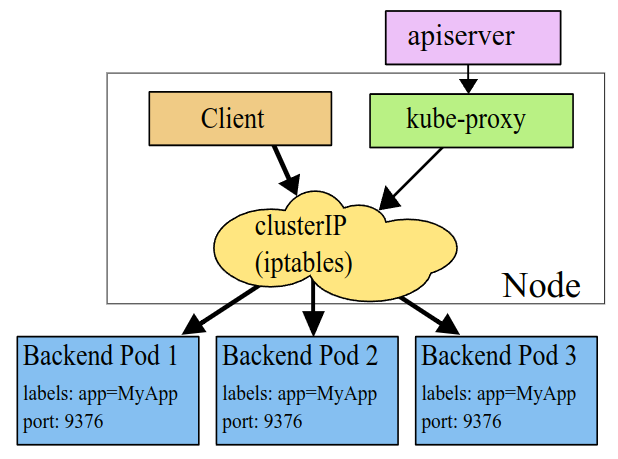
Fig 2.의 문제는 iptables에 서비스의 주소 (10.3.241.152)로 들어오는 패킷을 Server pod (10.0.2.2)로 보내는 rule을 추가하기만 하면 해결된다. Client가 10.3.241.152로 보낸 패킷은 노드의 iptables에 의해 10.0.2.2로 자동으로 전달된다.
남은 문제는 누가 iptables rule을 자동으로 관리해주는 지가 될 것이다. 이를 kube-proxy가 맡는다. kube-proxy는 API-server와 직접 통신하며 서비스와 엔드포인트 오브젝트의 추가, 제거를 감시한다. 서비스와 엔드포인트가 추가 혹은 삭제되면 그에 따라서 iptable rule을 추가 혹은 삭제한다.
Fig 2.의 상황에서 Server pod(10.0.2.2)가 에러에 의해 제거되고 새로운 Server pod(10.0.2.3)가 생겼다고 하자. 모든 노드에서 실행되고 있는 kube-proxy들은 이 정보를 가지고 iptables을 수정한다. 일단 10.3.241.152로 들어오는 패킷을 10.0.2.2로 보내는 rule을 삭제한다. 그 다음 10.3.241.152로 들어오는 패킷을 10.0.2.3으로 보내는 rule을 추가한다.
iptables은 이러한 NAT 기능 뿐만 아니라 load balance 기능도 수행한다. 따라서 한 서비스에 여러 Pod가 관리될 경우 load balance 알고리즘에 따라 Pod들에 트래픽을 분산한다.
ClusterIP 구현
위에서 설명한 내용을 Fig 4.를 통해 좀 더 구체적으로 정리해보자. ClusterIP는 클러스터 내에서만 유효한 가상 IP이기에 ClusterIP 유형 서비스는 파드간 통신을 위해 대부분 사용된다. Fig 4.에서 Pod A는 Service 1의 ClusterIP를 통해 접근하고자 한다. Pod A의 네트워크 트래픽은 Node 1에서 나가지 전 kube-proxy(iptables)의 Destination NAT(DNAT, 목적지 주소가 바뀌는 것)에 의해 목적지 주소가 서비스의 ClusterIP에서 Pod B의 ClusterIP로 바뀐다. Pod B이 보낸 응답 트래픽 또한 kube-proxy에 의해 소스(src)가 Pod B -> Service의 ClusterIP로 변경되어 Pod A로 전달된다. 이러한 과정을 통해 Pod A는 정상 통신되었다고 판단한다.

NodePort 구현
NodePort 유형 서비스는 노드의 IP를 빌려 외부 클라이언트가 파드에 접근할 수 있도록 한다. NodePort 유형 서비스는 노드의 Port를 예약하여 해당 Port로 들어온 트래픽을 자신(서비스)으로 전달하는 방식으로 작동한다. 서비스로 들어온 트래픽은 ClusterIP와 같은 방식으로 kube-proxy(iptables)을 통해 최종적으로 원하는 파드에 전달된다.
만약 30500번 포트를 사용하는 NodePort 유형 서비스가 등록되었다고 하자. 클러스터에 참여한 모든 워커노드의 30500번 포트로 들어온 트래픽은 해당 서비스로 전달된다. 여기서 쿠버네티스가 해줘야 할 일은 임의의 워커노드로 들어온 트래픽을 적절한 서비스로 전달해주어야 한다. 이 또한 kube-proxy가 수행한다.
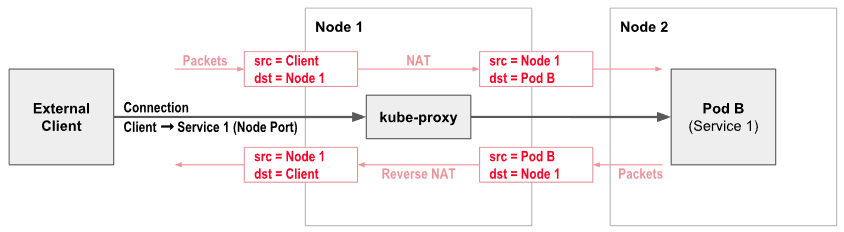
Fig 5.은 NodePort 유형 서비스에서 주소 변환을 잘 보여주는 그림이다. 외부 사용자(External Client)가 Node 1의 주소(=노드의 IP+Port)로 보낸 트래픽은 Kube-proxy에 의해서 서비스의 주소로 변환, 서비스의 주소는 최종적으로 Pod의 주소로 변환된다. 이러한 과정을 통해 트래픽은 적절한 Pod로 보내진다.
LoadBalancer 구현
LoadBalancer는 NodePort와 마찬가지로 External Client가 클러스터 내부 Pod에 접근할 수 있도록 하는 서비스 유형이다. 다만 LoadBalancer는 쿠버네티스 클러스터 이외에도 추가적으로 외부 Load balancer를 설치하거나 MetalLB와 같은 파드를 추가적으로 실행해주어야 한다. LoadBalancer는 NodePort에 비해 좀 더 구성하기 복잡하지만 NodePort의 단점을 극복할 수 있다.
이전 포스터에서도 정리하였지만 NodePort는 2가지 단점이 존재한다. Node의 IP를 통해 외부 클라이언트가 Pod에 접근하는데 노드는 언제든 고장날 수 있다는 것이다. 클러스터에 노드가 천개, 만개 있든 상관없이 내가 하나의 노드 IP만을 알고 있고, 그 노드가 고장이 나면 더이상 클러스터에 접근할 수 없다. 따라서 외부 클라이언트는 노드의 IP가 유효한지를 계속 관리해야 한다. 또한 노드로의 트래픽을 분산시킬 load balance가 없다. 1천개의 클라이언트가 노드 1번에 접근하더라도 다른 놀고 있는 노드로 트래픽을 분산할 방법이 없다.
외부 load balancer는 외부 클라이언트이 접근 가능한 하나의 공용 IP를 가지고 있다. 또한 외부 load balancer에 공용 IP로 들어온 트래픽을 전달해줄 노드들의 IP와 포트를 알려준다.
외부 클라이언트가 외부 load balancer에 접근하면 load balancer가 직접 등록된 노드들 중 하나를 선택하여 그 노드의 IP:Port 주소로 트래픽을 전달한다. 이제부터는 NodePort 유형의 서비스와 작동 방식이 똑같다. 노드의 IP:Port 주소로 들어온 트래픽은 해당 Node의 Port로 전달되고, kube-proxy에 의해 적절한 pod로 최종 전달된다.
여기서 공부가 부족한 부분이 외부 load balancer에 어떻게 쿠버네티스 클러스터의 모든 서비스 정보를 자동으로 등록하는 지이다. 외부 load balancer와 쿠버네티스 클러스터 간의 설정은 어떻게 하는 지를 공부하여 다음에 정리하도록 하겠다.
Reference
[1] https://medium.com/google-cloud/understanding-kubernetes-networking-pods-7117dd28727
[2] https://projectcalico.docs.tigera.io/about/about-kubernetes-services
'Cloud > Kubernetes' 카테고리의 다른 글
| Kubernetes 고가용성(HA) (2): kubeadm을 통한 고가용성 배포 (0) | 2023.01.04 |
|---|---|
| Kubernetes 고가용성(HA) (1): 고가용성과 Kube Master의 고가용성 (0) | 2023.01.04 |
| Pod 네트워크 (1) : Service 필요성과 개념, 종류 (ClusterIP, NodePort, LoadBalancer) (0) | 2022.12.15 |
| Kubespray를 통한 Kubernetes 배포(설치) (0) | 2022.12.13 |
| Pod 배포 - 워크로드 리소스 (2) (Daemonset, Job, Cronjob) (1) | 2022.12.07 |



