
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- convolution
- CUDA
- FPGA
- stl
- 양자역학의공준
- cloud
- POD
- HA
- nvidia
- deep_learning
- Semiconductor
- quantum_computing
- jhDNN
- CuDNN
- DRAM
- GPU
- 반도체
- kubernetes
- Compression
- SpMM
- C++
- jhVM
- 클라우드
- 반도체기초
- Qubit
- 쿠버네티스
- flash_memory
- sycl
- dnn
- 딥러닝
- Today
- Total
Computing
Kubernetes 고가용성(HA) (3): Keepalived와 HAProxy 본문
이전글
- Kubernetes 고가용성(HA) (1): 고가용성과 Kube Master의 고가용성
- Kubernetes 고가용성(HA) (2): kubeadm을 통한 고가용성 배포
이전 글에서 쿠버네티스 클러스터의 고가용성을 위한 Control plane(Master, 마스터) 다중화에 대해서 정리하고 간단한 Control plane 다중화 배포 실습을 진행하였다. 이전 실습에서는 HAProxy[2]를 사용하여 마스터간 로드 밸런싱을 구현하였고 이를 통해 마스터들의 API 서버간의 로드 밸런싱을 달성하였다.
실습을 간단히 정리하자면 다음과 같다. 3대의 마스터 A, B, C를 사용하는 환경에서 HAProxy를 A에 설치하였다(A가 Load Balancer 역할). 그리고 A의 36443 포트로 들어오는 트래픽을 A, B, C의 6443 포트로 전달하도록 HAProxy를 설정하였다. 다만 이러한 구성은 고가용성을 달성하지 못한다고 하였다. 고가용성이란 서버, 시스템 등이 지속적으로 정상 운영이 가능한 성질을 말한다[1]. 위 구성에서 마스터 B 혹은 C가 고장나도 다른 마스터만 살아있다면 정상 작동할 수 있다. 문제는 마스터 A가 고장나면 나머지 마스터 B, C 모두 접근할 수 없게 된다. 즉 시스템 전체가 고장나 정상 운영이 불가능한 것이다.
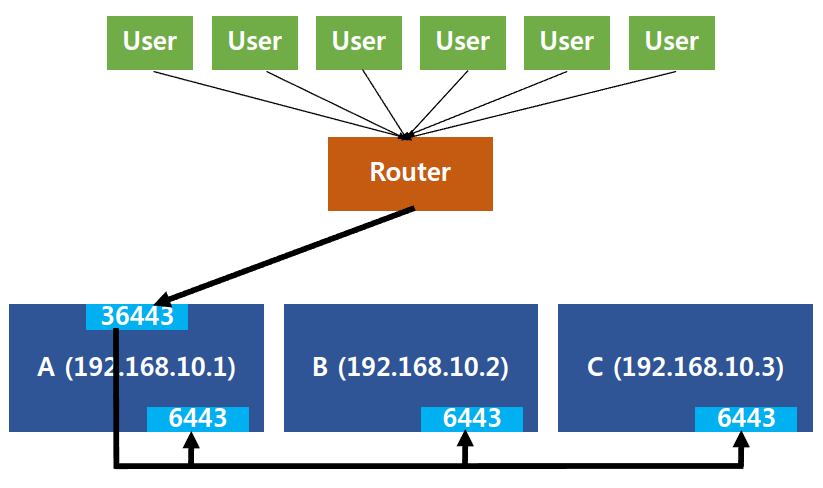
이를 해결하기 위해 Load Balancer(LB)가 고장날 경우를 대비한 장애 조치(failover) 설정이 필요하다. 오늘 포스터에서는 LB의 failover를 위한 Keepalived[3]에 대해서 정리해보고자 한다.
Keepalived
Keepalived는 load balancing(LB)과 high availability(HA)를 지원하기 위한 routing 소프트웨어이다[3]. 소프트웨어이기에 물리적인 하드웨어 설치가 필요하지 않고, 단순히 Keepalived를 컴퓨터에만 설치하면 해당 컴퓨터가 routing 기능을 수행할 수 있게 된다. Keepalived의 LB 기능은 Linux Virtual Server(IPVS) 커널 모듈을 이용하여 L4 LB를 지원한다(따라서 Keepalived는 Linux 시스템에서만 작동함). 또한 Keepalived의 HA 기능은 VRRP protocol[4]를 기반으로 작동한다.
(앞선 설명[3]에 따르면 L4 LB도 수행한다고 한다. 다만 Keepalived LB관련 자료가 별로 없고, 다른 사용자들도 고가용성 서버 구성을 위해 Keepalived(HA용) + HAProxy(LB용) 조합으로 많이 사용하기에 이번 포스터에서는 HA를 위한 Keepalived에 대해서만 정리하였다.)
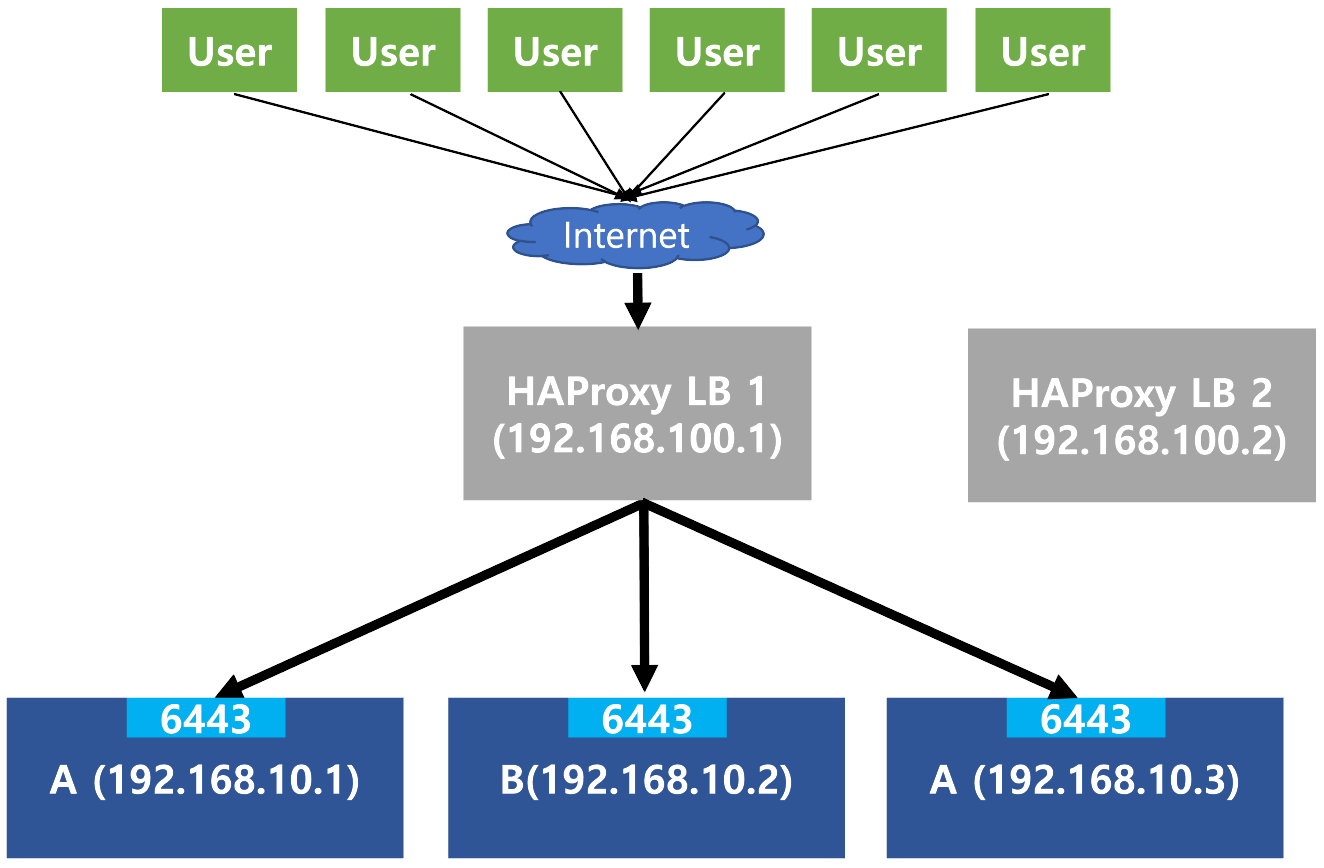
우선 Fig 2.와 같이 HAProxy LB가 포함된 시스템이 있다고 하자. (편의를 위해 Fig 1.과는 다르게 HAProxy만을 위한 서버를 따로 두었다) 위 구성에서 HAProxy가 설치된 서버(LB1)가 고장날 경우 전체 시스템이 고장난다. 이를 Single Point of Failure (SPOF)라고 한다. 이러한 SPOF를 방지하기 위한 가장 확실한 방법은 LB1이 고장날 경우를 대비한 여분의 LB2를 설치해 두는 것이다. 문제는 어떻게 User들에게 LB1이 고장났으면 LB2를 사용하라고 알려줄 수 있냐는 것이다.
다음과 같은 상황을 생각해 보자. 우선 어떤 서비스를 192.168.100.1 LB1를 이용하여 배포하였다. 사용자들은 192.168.100.1 주소를 외워 해당 서비스를 열심히 사용하였다. 그런데 갑자기 192.168.100.1 LB1에 고장이 발생하였다. 이러한 상황을 대비하기 위해 미리 192.168.100.2 LB2를 미리 세팅해두었고, 사용자들에게는 만약 192.168.100.1 주소가 작동하지 않는다면 192.168.100.2 주소를 사용하라고 알려두었다.
사용자들은 어떻게든 192.168.100.2 주소를 이용해 해당 서비스를 사용할 수는 있을 것이다. 다만 매우 불편한 사용환경이지 않는가? Keepalived는 이러한 문제를 해결하고, failover를 자동으로 지원한다. Keepalived는 Virtual IP address(VIP) 개념을 이용하여 이용하여 이러한 불편함을 해결하였다. Fig 3. Virtual IP address를 이용한 Keepalived의 failover 방식을 보여준다.
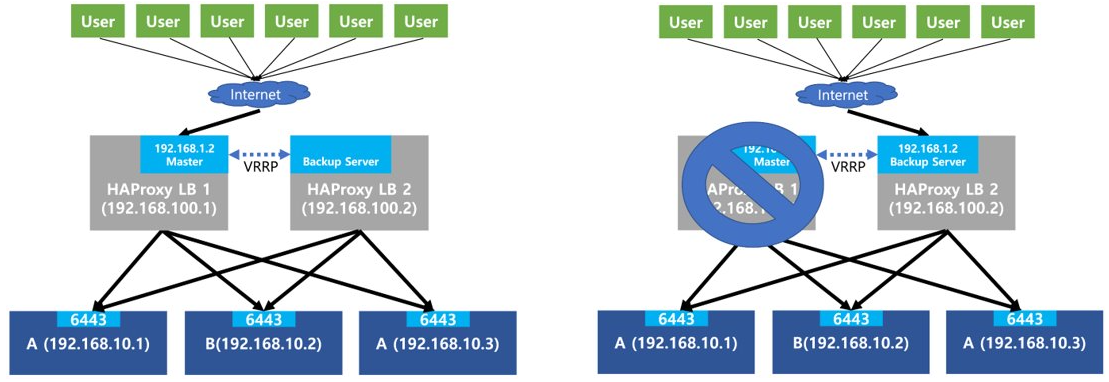
LB1과 LB2에 모두 Keepalived를 설치한다(Fig 3. LB 박스 안의 하늘색 박스 영역). LB1을 Keepalived Master, LB2를 Keepalived Backup 서버로 설정해둔다.
그리고 중요한 가상 IP(VIP) 개념이 등장한다. Keepalived는 Keepalived가 설치된 컴퓨터들 중 하나를 선택하여 해당 컴퓨터에 VIP를 자동으로 부여한다. Fig 3.의 왼쪽 그림에서 보듯 LB1에 [192.168.1.2]라는 VIP가 부여된다. 쉽게 생각하면 LB1은 두개의 IP [192.168.100.1]과 [192.168.1.2]를 동시에 가진 것과 같다. 즉 이제부터는 [192.168.1.2] 주소를 통해 사용자들은 LB1에 접근할 수 있게 된다.
만약 Fig 3.의 오른쪽과 같이 LB1이 고장났을 경우, Keepalived는 자동으로 VIP를 Backup 서버에 부여한다. (LB2에 설치된 Keepalived가 LB1이 죽었다는 것을 알아차려서, LB2가 [192.168.1.2] 주소를 가지도록 함) 즉 이제는 [192.168.1.2] 라는 VIP 주소로 네트워크 트래픽을 보낼 경우 LB1이 아닌 LB2로 전달된다. 이 경우에도 사용자는 편리하게 동일한 [192.168.1.2] 주소를 사용해서 서비스에 접근할 수 있다.
구체적으로 Keepalived는 VRRP 프로토콜을 이용하여 이러한 failover를 수행한다. Keepalived들은 active 혹은 standby 상태 중 하나를 가지는데, active 상태는 Keepalived들 중 하나만 가질 수 있고 나머지들은 모두 standby 상태를 가진다. Active 상태를 가진 Keepalived는 자신의 컴퓨터에 VIP를 부여하고, 나머지 standby Keepalived는 active Keepalived가 고장날 때까지 대기한다.
Active Keepalived는 VRRP를 통해 모든 standby Keepalived에게 자신이 살아있음을 반복적으로 알린다(VRRP Advertisement Packet 전송). 따라서 standby들은 VRRP 패킷을 받는다면 active가 살아있음을 확인하고 계속 대기 상태에 머무른다. 만약 active Keepalived에 문제가 발생하면 더이상 VRRP Packet을 전송할 수 없을 것이다. Standby들은 일정 시간동안 VRRP Packet이 도착하지 않는다면 active에게 문제가 생겼다고 판단한다. 그후 Standby 중 가장 우선순위가 높은 것이 active 상태가 되어 VIP를 자기 자신에게 부여한다. 이를 통해 중단 없는 VIP 지원이 가능해지는 것이다.
Reference
[1] https://ko.wikipedia.org/wiki/%EA%B3%A0%EA%B0%80%EC%9A%A9%EC%84%B1
[3] https://www.keepalived.org/
[4] https://en.wikipedia.org/wiki/Virtual_Router_Redundancy_Protocol
'Cloud > Kubernetes' 카테고리의 다른 글
| Pod 스토리지 (1): Volume, PersistentVolume, PersistentVolumeClaim 개념 (0) | 2023.05.04 |
|---|---|
| Kubernetes 고가용성(HA) (4): Heartbeats (0) | 2023.04.27 |
| Pod 네트워크 (4) : LoadBalancer와 MetalLB (load balancing 개념, MetalLB 역할) (0) | 2023.03.27 |
| Pod 네트워크 (3) : kube-proxy와 CNI plugin 차이 (0) | 2023.01.27 |
| Kubernetes 고가용성(HA) (2): kubeadm을 통한 고가용성 배포 (0) | 2023.01.04 |



