
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- stl
- GPU
- Semiconductor
- 반도체기초
- nvidia
- dnn
- kubernetes
- SpMM
- POD
- FPGA
- 양자역학의공준
- 딥러닝
- sycl
- 쿠버네티스
- convolution
- CuDNN
- Compression
- flash_memory
- DRAM
- 클라우드
- 반도체
- jhDNN
- quantum_computing
- C++
- HA
- CUDA
- Qubit
- cloud
- deep_learning
- jhVM
- Today
- Total
Computing
jhDNN - 3 : Convolution 연산 및 GEMM-Convolution에 대한 고찰 (Feat. im2col) 본문
jhDNN - 3 : Convolution 연산 및 GEMM-Convolution에 대한 고찰 (Feat. im2col)
jhson989 2022. 4. 26. 23:01Convolution primitive 분석 및 최적화 방법
Convolution primitive는 딥러닝, 특히 computer vision 분야에서 중요한 연산 중 하나이다. 전통적인 computer vision 및 signal processing 영역에서 convolution(or correlation)은 pattern matching에 좋은 연산자이다. 이런 특성이 딥러닝을 이용한 computer vision 분야에서도 활용되는데, convolution layer는 pattern recognition을 통해 이미지 특징(feature)을 추출한다. (locality) Spatially 이웃한 데이터들간의 상관관계를 파악하여 특징을 추출하며, pooling layer와 함께 사용되어 점점 큰 영역의 패턴 추출까지 진행한다. Fig 1.은 이러한 convolution primitive의 작동 원리에 대해서 잘 보여주는 그림이다. 이때, convolution layer는 이미지의 모든 영역에서 동일한 filter를 이용해 sliding window 방식으로 특징 추출하므로 tranlation invariance 특징을 가진다.
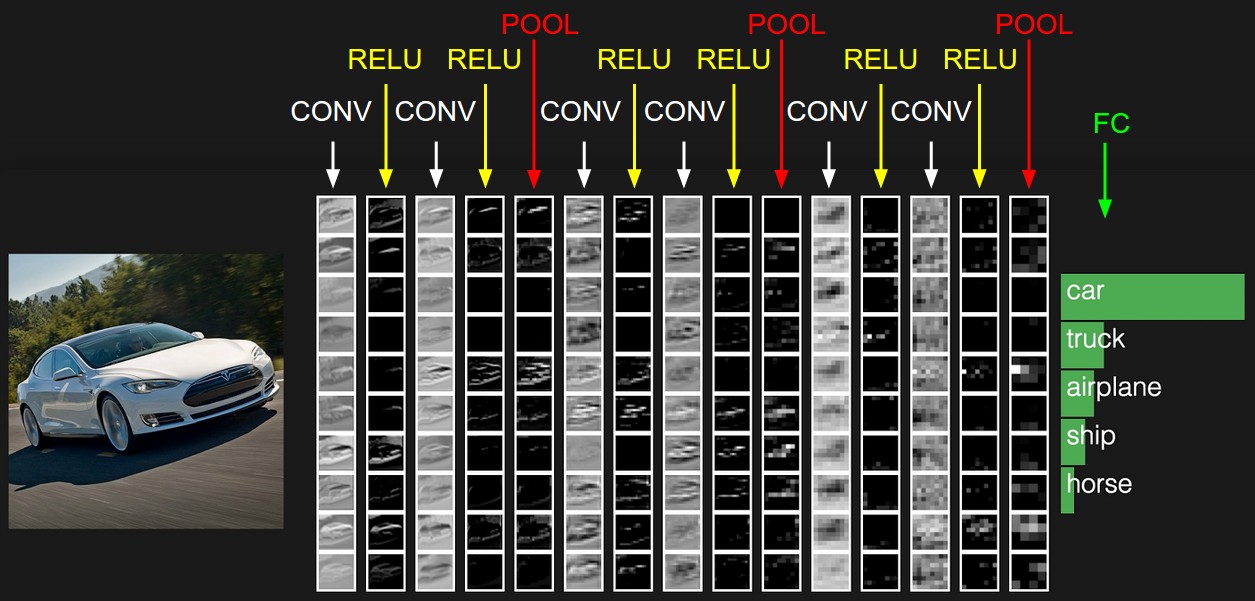
Convolution primitive는 computer vision에서 많이 사용되기에 딥러닝 네트워크의 전체 계산량에서 큰 비중을 차지한다. 따라서 Amdahl's law에 따라 convolution layer의 최적화는 딥러닝 네트워크 학습 및 추론 계산 속도 향상에 크게 기여할 것이다. (대표적인 CNN의 구체적인 convolution layer의 계산 비중에 대해서 한번 조사해봐야 겠다.)
NVIDIA GPU를 통한 딥러닝 가속를 위한 library인 cuDNN은 이러한 convolution operation의 최적화 구현을 제공한다. Fig 2.는 cuDNN에서 지원하는 convolution forward의 알고리즘 리스트[2]인데, 정리하면 cuDNN에서는 크게 4가지 convolution 최적화 알고리즘을 제공한다. 각각 direct convolution, GEMM을 이용한 convolution, FFT을 이용한 convoltion, winograd을 이용한 convolution이다.

Direct convolution은 우리가 잘 알고 있는일반적인 cross-correlation 연산을 의미한다. Fig 3.은 direct convolution의 예시를 보여주는데, input image에 convolution layer의 filter를 cross-correlation 연산한다. Filter를 sliding window 방식으로 모든 이미지 영역에서 cross-correlation 값을 계산하면, 이 결과값이 output이 된다.

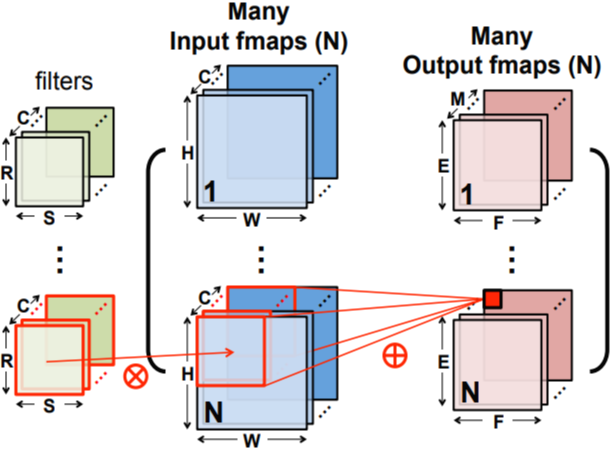
실제로 병렬로 구현해보면 매우 최적화하기 어려운 연산이다. 일반적으로 Input image은 4차원 tensor(N*C*H*W)이며 filter와 output 또한 4차원 tensor이다. Fig 4.는 각 tensor의 크기 및 계산 과정을 잘 나타내는 그림이다. 이때 output tensor를 계산하기 위해서는 7중 for문으로 구현하게 된다. 7개 for문은 각각 mini-batch, output_channel, output_height, output_width, input_channel, input_height, input_width 차원을 iterate한다. 뿐만 아니라, stride와 padding, dilation까지 고려한다면 매우 branch가 많은 연산이 된다. 따라서 GPU와 같은 SIMD, SPMD, SIMT 아키텍처에서는 branch divergence에 의해 성능 하락이 심하게 발생할 것이다. 이에 따라 병렬 처리를 통한 성능 향상에는 한계가 있을 것이다.
GEMM을 이용한 Convolution : Im2Col
Direct convolution의 한계를 극복하기 위한 최적화 기법 중 가장 쉽게 구현할 수 있는 것이 바로 GEMM (GEneral Matrix to Matrix Multiplication) 을 통한 구현일 것이다. GEMM은 matrix multiplication의 가장 일반화된 식으로 Eq 1.과 같다.

GEMM은 GPU를 통해 최적화하기 쉬운 연산으로 이미 극한으로 최적화된 많은 implementation이 존재한다. 만약 input이미지만을 특별한 형태(col)로 변환한다면, input과 kernel의 GEMM으로 convolution 연산을 구현할 수 있다. 이 input을 특별한 형태, col으로 바꾸는 연산을 Im2Col이라고 한다. Im2Col을 이용한 GEMM-convolution은 Fig 5.과 같이 작동한다.
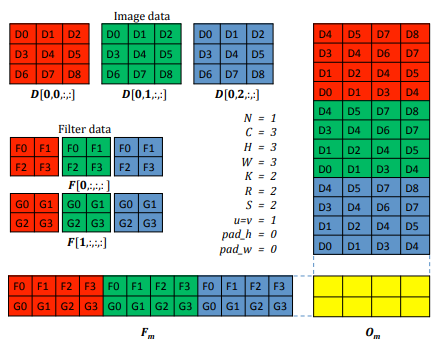
Filter는 그대로 두고 (4차원 filter tensor를 2차원 matrix로 생각하기만 하면 된다.) input data를 그림과 같이 col으로 바꾼다. 이후 2D filter matrix와 2D col matrix 간의 GEMM 연산을 하면 2D output을 얻을 수 있다. 결과로 나오는 2D output은 3D output tensor(CHW)와 같은 배열로, 변환할 필요 없이 우리가 원하는 결과를 얻을 수 있다. 정리하자면 (1)input을 col으로 바꾸기, (2) filter와 col의 GEMM 계산으로 GEMM-convolution은 진행된다.
GEMM은 빠른 연산이 가능하지만, GEMM based convolution을 위해서는 2가지 overhead가 발생한다. 첫 번째는 Input을 column matrix로 바꾸는 overhead와 두 번째는 column matrix를 저장하기 위한 memory overhead이다.
Column matrix의 크기는 Batch * Filter_channel * Filter_height * Filter_width * Output_height * Output_width이다. Output의 크기가 input과 비슷하다고 가정할 경우, filter의 size(채널, 넓이, 높이 모두)에 비례하여 column matrix의 크기가 결정된다. 따라서 filter의 channel이나 filter의 크기가 큰 convolution layer에서는 매우 큰 영역의 데이터를 사용한다. 예를 들어 filter가 3*3*3일 경우, 실제 input에 비해 27배나 더 큰 메모리 공간을 차지하게 된다.
Input을 column matrix로 바꾸는 연산의 overhead는 실제로 구현해보면 생각보다는 크지 않다. 다만 convolution layer가 반복해서 사용되는 딥러닝 네트워크 학습에서는 이러한 overhead가 쌓여서 큰 overhead가 될수도 있을 것이다.
Im2Col vs. Filter2Row
Image를 변환하는 것이 아닌 kernel을 변환하면(Filter2Row), 매 학습 및 추론에서 발생하는 변환 overhead를 제거할 수 있다.
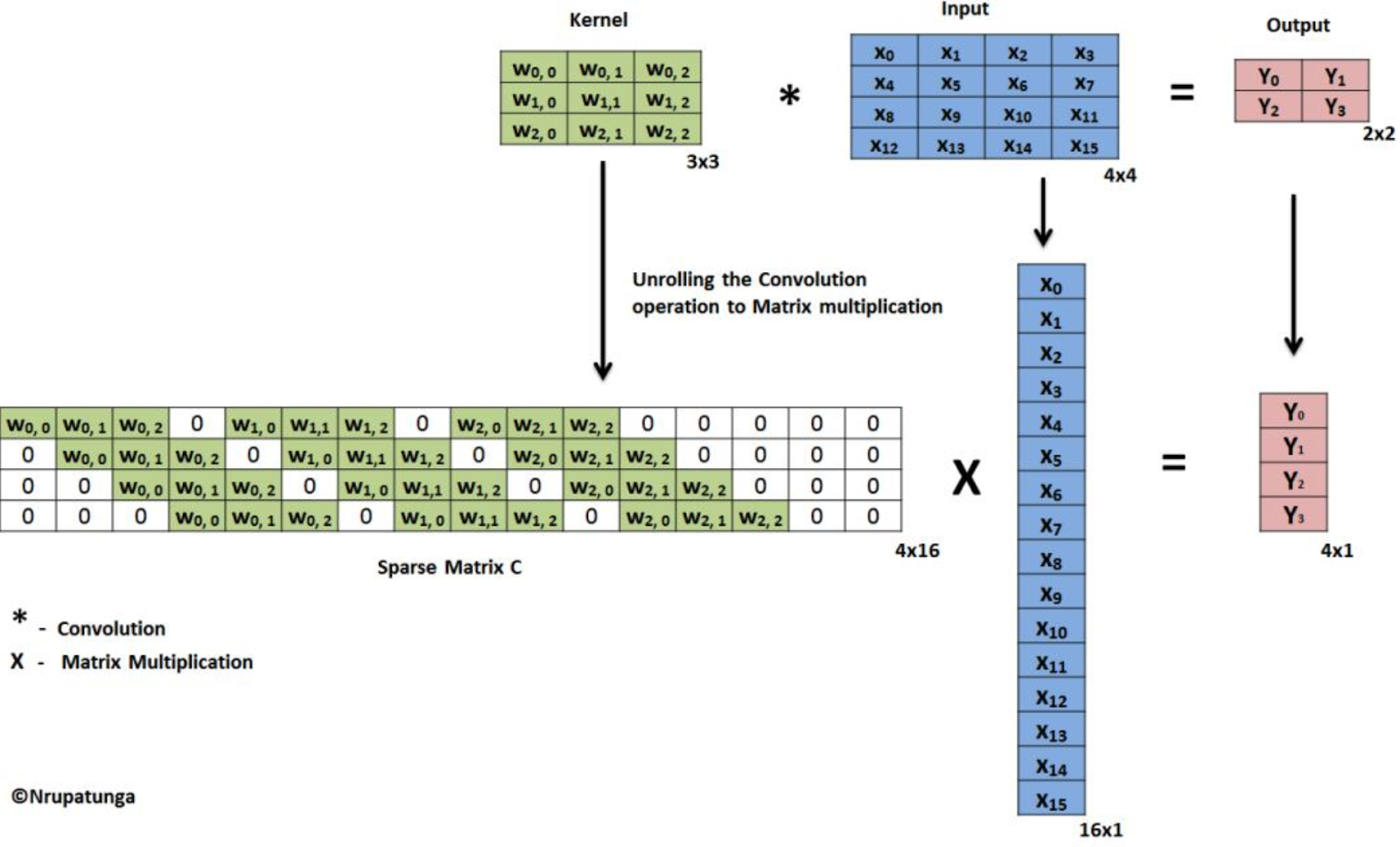
Fig 6.은 Filter2Row를 나타낸 그림이다. Kernel을 row matrix로 저장할 경우, 처음 한번만 변환하면 되고 이후에는 변환된 kernel을 사용하면 된다. 따라서 변환 overhead는 0에 수렴한다.
다만 row matrix의 크기는 Batch * Output_channel * Output_height * Output_width * Input_channel * Input_height * Input_width이다. 즉 row matrix의 크기는 input과 output 크기의 곱에 의해 결정된다. Im2Col의 col matrix의 크기는 output과 kernel의 크기의 곱에 의해 결정된다.
일반적인 경우 output 크기가 kernel의 크기보다 매우 크기에 Im2Col에 비해 Filter2Row는 매우 큰 메모리 공간을 차지할 것이다. 변환 overhead가 사라진다는 장점이 있지만 메모리 공간 사용에 매우 큰 한계가 있는 것이다. 다만 kernel의 크기가 output의 크기와 비슷한 경우 Filter2Row 사용의 장점이 있을 것으로 예상된다.
Implementation
GitHub - jhson989/fast-conv: Fast Convoluion Implementation via CUDA
Fast Convoluion Implementation via CUDA. Contribute to jhson989/fast-conv development by creating an account on GitHub.
github.com
위 프로젝트의 "include/conv_gpu_matmul.cuh"에 im2col 및 GEMM-convolution을 구현해 놓았다. Im2Col의 경우 어떻게 최적화해야 할 지 감이 안잡혀서 아직은 최적화가 덜 되었다. 계속해서 최적화 방향에 대해서 고민을 해보아야겠다.
Reference
[1] https://cs231n.github.io/convolutional-networks/
[2] https://docs.nvidia.com/deeplearning/cudnn/api/index.html#cudnnConvolutionFwdAlgo_t
[3] https://www.ibm.com/cloud/learn/convolutional-neural-networks
[4] Sze, Vivienne. Efficient Processing of Deep Neural Networks: from Algorithms to Hardware Architectures. NeurIPS 2019 tutorial.
[5] S. Chetlur, C. Woolley, P. Vandermersch, J. Cohen, J. Tran, B. Catanzaro, and E. Shelhamer, “cudnn: Efficient primitives for deep learning,” arXiv preprint arXiv:1410.0759, 2014.
[6] Nrupatunga
'Deep Learning > jhDNN' 카테고리의 다른 글
| cuDNN Convolution FWD Algorithm 분석 (2) 성능 분석 with 일반 데스크탑 (0) | 2022.05.08 |
|---|---|
| cuDNN Convolution FWD Algorithm 분석 (1) Overview (0) | 2022.05.04 |
| cuDNN Graph API (1) (Feat, Operator Fusion & TVM) (0) | 2022.05.03 |
| jhDNN - 2 : cuDNN Convolution Forward 방법 (0) | 2022.04.19 |
| jhDNN - 1 : cuDNN 소개 및 설치 (Ubuntu 18.04) (0) | 2022.04.19 |

