
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- quantum_computing
- HA
- FPGA
- dnn
- 딥러닝
- 쿠버네티스
- GPU
- Qubit
- jhVM
- 반도체
- 양자역학의공준
- CUDA
- sycl
- DRAM
- convolution
- Compression
- jhDNN
- CuDNN
- 클라우드
- kubernetes
- nvidia
- C++
- deep_learning
- flash_memory
- stl
- SpMM
- cloud
- 반도체기초
- POD
- Semiconductor
Archives
- Today
- Total
Computing
cuDNN Convolution FWD Algorithm 분석 (2) 성능 분석 with 일반 데스크탑 본문
Deep Learning/jhDNN
cuDNN Convolution FWD Algorithm 분석 (2) 성능 분석 with 일반 데스크탑
jhson989 2022. 5. 8. 00:38이전 글 : 2022.05.04 - [Deep Learning/jhDNN] - cuDNN Convolution FWD Algorithm 분석 (1) Overview
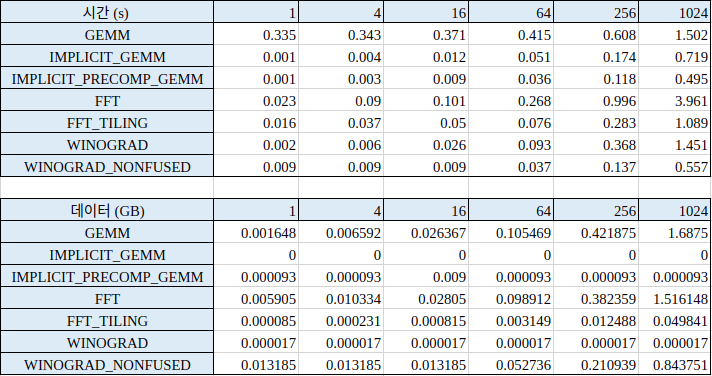
이전 글에서 cuDNN의 convolution forward algorithm에 대하여 간략히 분석해 보았다. 오늘은 각 알고리즘의 성능을 많이 사용되는 convolution layer configuration 별로 정리하고자 한다.
실험 환경
이 실험은 게임 실행을 위해 설계된 데스크탑 시스템에서 진행되었다. 일반적인 게이밍 환경에서의 결과 리포트는 이것이 (거의) 처음일 것이니, 이 실험 환경 또한 큰 기여를 할 것이라고 생각한다. Table 1.은 실험 환경을 정리한 표이다.

모든 실험은 50회 반복 실행한 결과이며, 시간은 50회 실행 결과의 합이다. 따라서 실제 한 번 실행은 시간을 50으로 나눠줘야 구할 수 있다.
Kernel Size (Filter_Height, Filter_Width)에 따른 성능
Kernel Size (Input_Channel, Output_Channel)에 따른 성능
Mini-Batch Size에 따른 성능
'Deep Learning > jhDNN' 카테고리의 다른 글
| cuDNN Convolution FWD Algorithm 분석 (1) Overview (0) | 2022.05.04 |
|---|---|
| cuDNN Graph API (1) (Feat, Operator Fusion & TVM) (0) | 2022.05.03 |
| jhDNN - 3 : Convolution 연산 및 GEMM-Convolution에 대한 고찰 (Feat. im2col) (1) | 2022.04.26 |
| jhDNN - 2 : cuDNN Convolution Forward 방법 (0) | 2022.04.19 |
| jhDNN - 1 : cuDNN 소개 및 설치 (Ubuntu 18.04) (0) | 2022.04.19 |
'Deep Learning/jhDNN' Related Articles
more

