
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 클라우드
- 양자역학의공준
- jhVM
- GPU
- cloud
- CUDA
- quantum_computing
- HA
- FPGA
- 쿠버네티스
- Qubit
- convolution
- dnn
- kubernetes
- C++
- POD
- 딥러닝
- CuDNN
- stl
- jhDNN
- sycl
- Compression
- 반도체기초
- nvidia
- flash_memory
- SpMM
- Semiconductor
- DRAM
- 반도체
- deep_learning
- Today
- Total
Computing
Algorithm) Parallel Merge sort 본문
Merge sort 개념
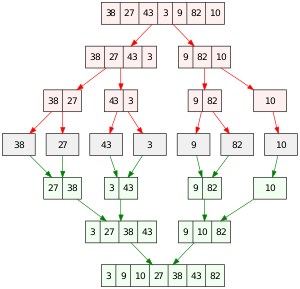
다음 그림과 같이 Two pass (그림 상의 빨간색 과정과 초록색 과정)로 진행됩니다. 빨간색 과정을 Divide path, 초록색 과정을 combine path라고 하겠습니다.
[Divide path]
Divide path의 경우 Recursively 현재 array를 두개의 연속된 half-arrays로 분할합니다. half-array의 크기가 1이 될때까지 분할합니다.
[Combine paht]
Combine path의 경우 Recursively 두개의 half-arrays를 합쳐서 하나의 arrays로 정렬합니다. 이때 두 개의 half-arrays는 항상 정렬되어 있기에 두개의 half-arrays를 쉽게 정렬할 수 있습니다. (항상 정렬되어있는 이유는 귀납적으로, half-array의 크기가 1일때 정렬되어 있음. half-array의 크기가 n일때 정렬되어 있으면, 두 half arrays를 합쳐서 정렬한 2*n 크기의 array도 정렬되어 있음)
(ascending order 정렬 가정) 정렬하는 방법은 다음과 같습니다. 두 half-arrays(left, right라 하면)의 첫번째 element들을 비교, 작은 것을 선택하고 full-array에 push합니다. half-array들의 모든 elements가 full-array에 push될때까지 이 과정을 반복하면 full-array는 정렬된 상태가 됩니다.
Parallel Optimization strategy
Merge sort의 경우 recursive function으로 쉽게 구현할 수 있습니다. Recursive function의 경우 OpenMP[1] tasks를 이용하면 쉽게 병렬화할 수 있습니다.
Divide 과정의 통해 생성된 두 half-arrays는 두 threads가 독립적으로 정렬할 수 있습니다. 정렬된 두 half-arrays를 하나의 full-array로 합치는 과정은 병렬화하는 것보다는 하나의 thread로 처리하도록 구현하는 것이 더 효율적일 것이라 판단하였습니다.
따라서 half-arrays로 OpenMP task로 생성하여 병렬적으로 정렬합니다. 정렬된 half-arrays들을 하나로 합치는 combine path는 하나의 thread가 처리합니다.
이때 task를 너무 많이 생성하는 것은 오히려 overhead를 발생시키기에, recursive function call의 depth가 3일때까지만 two half-array 정렬을 병렬화하였습니다. 즉 half-arrays의 크기가 N/8가 될 때까지만 병렬적으로 처리하도록 하였습니다.
Implementation
OpenMP을 사용하여 구현하였습니다.
https://github.com/jhson989/ParallelMergeSort
GitHub - jhson989/ParallelMergeSort: Parallel Merge Sort Implemented via OpenMP
Parallel Merge Sort Implemented via OpenMP. Contribute to jhson989/ParallelMergeSort development by creating an account on GitHub.
github.com
테스트 환경은 다음과 같습니다.
- CPU: 6 physical cores를 가지는 AMD Ryzen 5 3500x -> 6 openmp threads를 사용함
- Memory: 16 GB DRAM (3200MHz, 2 slots used - each socket is occupied by a 8 GB DRAM)
성능 결과는 다음과 같습니다.
- Problem: N=2^29 개의 random double type variables
- std::sort 이용 시: 169s
- Naive sequential merget sort: 179s
- OpenMP task based parallel merge sort (6 threads): 49s
- 결론: std::sort 대비 parallel implementation은 3.4x speed up 달성
Naive sequential merget sort은 제가 직접 짠 merge sort로 최적화가 부족해 std::sort에 비해서는 성능이 떨어지는 것 같습니다.
Parallel implementaion의 경우, std::sort 대비 3.4x speed up 달성하였습니다. Sorting은 가벼운 computation을 가지는데 비해 (단순 크기 비교만 함) memory operation(값 swap 등)이 많아 threads 개수 대비 성능 향상에 제한이 있는 것으로 생각됩니다.
'Parallel | Distributed Computing > 알고리즘' 카테고리의 다른 글
| BLAS란? (AXPY, GEMV, GEMM 연산자) (0) | 2022.07.07 |
|---|---|
| Parallel Matrix Transpose : Coalesced Memory Access & Bank Conflicts (SYCL 구현) (0) | 2022.04.27 |
| SpMM - 3 : CSR 변환 GPU 병렬 알고리즘 (0) | 2022.03.29 |
| SpMM - 2 : Sparse Matrix Representation (0) | 2022.03.22 |
| SpMM - 1 : Introduction (0) | 2022.03.22 |



