
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- quantum_computing
- SpMM
- 양자역학의공준
- jhVM
- 클라우드
- C++
- convolution
- DRAM
- HA
- nvidia
- sycl
- deep_learning
- POD
- CuDNN
- 반도체
- kubernetes
- GPU
- FPGA
- CUDA
- 반도체기초
- 쿠버네티스
- Qubit
- Compression
- Semiconductor
- jhDNN
- dnn
- flash_memory
- 딥러닝
- cloud
- stl
- Today
- Total
목록GPU (6)
Computing
 NCCL 개념 및 Ring 기반 집합 통신 최적화
NCCL 개념 및 Ring 기반 집합 통신 최적화
이전글 2022.04.04 - [Parallel Computing/개념] - Collective communication 이전에 collective communication 집합 통신에 대하여 정리한 적이 있었다. 집합 통신은 여러 개의 프로세스(or thread) 간의 데이터를 전송하는 통신 패턴을 의미하는 것으로, 2개의 프로세스간 통신(Point-to-point communication)과 대비되는 개념이다. 오늘은 이 여러 개의 GPU들간의 집합 통신을 구현한 NVIDIA NCCL에 대하여 정리하면서, NCCL의 집합 통신 최적화의 기본 아이디어인 Ring 기반 집합 통신 최적화 방법에 대해서도 정리하고자 한다. Collective Communication 집합 통신 2개의 프로세스간의 통신 패턴..
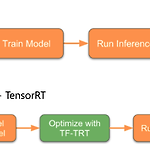 TensorRT (3) TF-TRT (TensorFlow integaration with TensorRT) 소개 및 구현 예제
TensorRT (3) TF-TRT (TensorFlow integaration with TensorRT) 소개 및 구현 예제
이전 글 2022.06.14 - [Deep Learning/Optimization (Algorithm)] - TensorRT (1) 개념, 최적화 방법, Workflow (Layer Fusion, Quantization 등) 2022.07.08 - [Deep Learning/Optimization (Algorithm)] - TensorRT (2) 설치 및 샘플 테스트 (Ubuntu 18.04 기준) 이전 글들에서 TensorRT의 기본 개념 및 설치 방법에 대하여 알아보았다. 이번 포스터에서는 TensorFlow 딥러닝 네트워크를 TensorRT로 최적화하는 방법에 대하여 정리하고자 한다. TensorFlow의 TensorRT integration 문서[1]를 참고하여 정리하고자 한다. TF-TRT Te..
 TensorRT (1) 개념, 최적화 방법, Workflow (Layer Fusion, Quantization 등)
TensorRT (1) 개념, 최적화 방법, Workflow (Layer Fusion, Quantization 등)
NVIDIA TensorRT는 "A high-performance deep learning inference SDK for production environments" 이다. 즉 실제 딥러닝이 배포되는 환경에서 NVIDIA GPU를 이용해 딥러닝 추론을 가속 & 최적화 할 수 있는 SDK이다. 이번 포스터에서는 빠르고 효율적인 추론만을 위해 설계된 TensorRT에 대해서 정리해보고자 한다. TensorRT가 도입된 배경 및 간략한 소개 딥러닝 네트워크의 정확도 향상을 위해 딥러닝 네트워크가 깊어지고 더 많은 parameters를 가지면서, 네트워크 추론을 위한 연산량은 계속 증가하고 있다. 연산량의 증가는 곧 긴 추론 시간, 많은 메모리 사용, 많은 전력 사용을 의미할 것이다. 음성 인식, 번역, 자율..
 GPU 프로그램이 느린 이유 - 1 : Memory Bound
GPU 프로그램이 느린 이유 - 1 : Memory Bound
GPU 프로그램이 빠른 이유 GPU는 대표적인 manycore processor들 중 하나[1]로, 4개 혹은 8개의 core를 가지는 일반 CPU와는 다르게 수 천개의 core를 가지고 있다. 이렇게 많은 core를 이용하여 각 데이터를 독립적으로 계산하는 data parallellim을 달성한다. Fig 1.는 CPU와 GPU의 하드웨어 디자인 방향이 어떻게 다른 지를 보여준다. 초록색 영역은 ALU (arithmetic logic unit)으로 실제 계산이 이뤄지는 영역이며, 각 ALU(초록 박스 하나하나)는 독립적으로 instruction stream(thread)을 계산할 수 있다.. 노란색 영역은 Control logic 영역으로 명령어를 해석하고 instruction 실행 최적화를 계산한다...
 SpMM - 3 : CSR 변환 GPU 병렬 알고리즘
SpMM - 3 : CSR 변환 GPU 병렬 알고리즘
Compressed Sparse Row Format SpMM - 2 : Sparse Matrix Representation 이전 포스터에서 sparse matrix가 무엇인지를 정의하고 왜 필요한지를 알아보았다. SpMM - 1 : Introduction Sparse Matrix Multiplication Matrix multiplication은 우리가 흔히 아는 다음 그림과 같은 행렬곱.. computing-jhson.tistory.com 저번 포스팅을 통해 sparse matrix를 저장하기 위한 다양한 형식을 배웠으며, 오늘은 CSR, Compressed Sparse Row format을 어떻게 구현하는 지에 대하여 정리할 것이다. 특히 [1]를 참고하여, GPU 디바이스를 통한 CSR 변환 가속화..
 NVIDIA : Tensor core
NVIDIA : Tensor core
Tensor core는 NVIDIA GPU volta architecture(2018)부터 등장한 Matrix multiply-accumulate (MMA) 연산을 지원하기 위한 specialized computing unit이다. 다양한 NPU(Google의 Tensor Processing Unit 등)들과 같이, 딥러닝이 대세가 되고 matrix-multiplication이 많은 애플리케이션에서 주요한 성능 병목이 되면서 NVIDIA가 GPU에도 탑재한 것으로 생각된다. 이번 포스트에서는 다음 논문을 읽고 Tensor core에 대하여 정리해보고자 한다. Programmability와 성능, 한계 등에 대하여 매우 자세히 분석해놓은 논문이다. Markidis, Stefano & Chien, Steve..