
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- 양자역학의공준
- nvidia
- convolution
- stl
- 쿠버네티스
- DRAM
- jhVM
- sycl
- GPU
- CuDNN
- jhDNN
- Semiconductor
- flash_memory
- dnn
- FPGA
- SpMM
- 딥러닝
- C++
- HA
- Compression
- cloud
- deep_learning
- 반도체
- POD
- Qubit
- quantum_computing
- kubernetes
- CUDA
- 클라우드
- 반도체기초
- Today
- Total
Computing
TensorRT (1) 개념, 최적화 방법, Workflow (Layer Fusion, Quantization 등) 본문
TensorRT (1) 개념, 최적화 방법, Workflow (Layer Fusion, Quantization 등)
jhson989 2022. 6. 14. 21:49NVIDIA TensorRT는 "A high-performance deep learning inference SDK for production environments" 이다. 즉 실제 딥러닝이 배포되는 환경에서 NVIDIA GPU를 이용해 딥러닝 추론을 가속 & 최적화 할 수 있는 SDK이다. 이번 포스터에서는 빠르고 효율적인 추론만을 위해 설계된 TensorRT에 대해서 정리해보고자 한다.
TensorRT가 도입된 배경 및 간략한 소개
딥러닝 네트워크의 정확도 향상을 위해 딥러닝 네트워크가 깊어지고 더 많은 parameters를 가지면서, 네트워크 추론을 위한 연산량은 계속 증가하고 있다. 연산량의 증가는 곧 긴 추론 시간, 많은 메모리 사용, 많은 전력 사용을 의미할 것이다. 음성 인식, 번역, 자율 주행, 물체 검출 등의 딥러닝 네트워크가 많이 사용되고 있는 분야를 생각해보자. 이러한 애플리케이션은 높은 정확도, 낮은 응답 시간, 효율적인 전력 및 메모리 사용을 달성하여야 한다.
- 높은 정확도 : 딥러닝 네트워크의 추론 정확도가 높아야 함
- 낮은 응답 시간 (Low response time) : 자율주행차, 번역 등 실사용되는 환경에서는 빠른 추론이 필요
- 효율적인 전력 및 메모리 사용 (Power & memory efficiency) : 우리가 딥러닝 네트워크를 학습시키는 환경(ex, 데이터 센터)과 제품으로서 실제 사용되는 환경(ex, 휴대폰, 자동차)은 많은 차이가 존재. 제품이 실제 사용되는 환경에서는 메모리의 양이 제한되며, 사용가능한 전력(배터리를 이용)도 제한됨.
TensorRT는 실사용 환경에서 inference 과정을 자동 최적화하여 낮은 응답 시간과 효율적인 전력 및 메모리 사용 달성하고자 한다. 즉 TensorRT는 다양한 딥러닝 프레임워크 (Caffe, Pytorch, Tensorflow 등)에서 학습된 네트워크 및 실사용 환경(데이터센터, PC, embed system, 자동차 등)을 분석하여 자동으로 최적화된 딥러닝 네트워크를 생성한다. 이렇게 생성된 최적화된 딥러닝 네트워크는 해당 환경에서 일반 딥러닝 프레임워크에 비해 매우 향상된 성능을 보인다. Fig 1.은 TensorRT의 ecosystem을 보여주는 것으로, 다양한 프레임워크를 통해 학습이 완료된 네트워크를 다양한 실사용 환경에서 최적 배포할 수 있도록 도와준다.

TensorRT의 네트워크 최적화 방법
Fig 2.은 TensorRT 공식 홈페이지에서 제공하는 다이어그램으로 TensorRT의 작동 방식을 잘 나타낸다. TensorRT는 학습된 딥러닝 네트워크 (trained neural network) 를 입력으로 받아, 추론에 최적화된 딥러닝 네트워크 엔진 (optimized inference engine) 을 출력한다.
TensorRT는 이러한 최적화 과정을 자동으로 수행하며, 배포 시 TensorRT를 통해 자동 최적화만 하더라도 동일한 GPU 시스템에서 몇 배 이상의 추론 속도 향상을 달성할 수 있다[1]. 최적화된 추론 엔진은 Python 혹은 C++ 프로그램에서 TensorRT API를 통해 load되어 추론에 사용될 수 있다. (자동화된 code 및 performance analysis, 그것을 통한 optimized code generation 등의 기술이 돋보인다.)
Fig 2.에서 확인 가능하듯 TensorRT가 수행하는 최적화는 총 6가지이며 다음과 같다.
- Reduced Precision : 딥러닝 네트워크의 정확도를 유지하면서 FP32 연산을 FP16 (AMP) 혹은 INT8 (Quantization) 연산으로 바꿔 성능 향상을 달성함. 낮은 정확도를 가지는 데이터 타입 연산은 더 적은 메모리 사용량, 더 빠른(?) 메모리 접근, 더 빠른 계산 (Tensor core와 같은 specialized hardware unit을 사용할 수도 있음) 을 가능하게 함.
- Layer and Tensor Fusion : Operator fusion이라고도 하는데, 몇가지 Layer들을 하나의 layer로 합침. 이를 통해 data reuse 를 늘려 DRAM or off-chip memory 접근을 줄임. 이를 통해 성능 향상을 달성함.
- Kernel Auto-Tuning : 딥러닝 네트워크가 배포되는 시스템에 맞게 최적화된 GPU kernel tuning을 지원함. GPU는 어디에 사용되는 지 (데이터센터용 100시리즈, 임베디드용 jetson, 자율주행용 DRIVE), 어떤 세대인지 (Volta, Ampere, Hopper), 어떤 용도로 사용되는 지 (렌더링, HPC, 게임) 등 여러 조건에 따라 매우 다양한 아키텍처를 가짐. 각 아키텍처마다 최적 kernel parameters (thread block configuration, data layout, shared memory 등등) 가 달라질 것인데, 타겟이 되는 각 GPU 시스템에 맞게 이러한 kernel parameters를 자동으로 선택해줌.
- Dynamic Tensor Memory : GPU 메모리 사용량 최적화 및 재활용. GPU 메모리 할당 (malloc) 및 해제 (free) 는 매우 비싼 operation. 따라서 한번 GPU 메모리 영역을 할당하고, 그것을 반복해서 사용하는 것이 필수. TensorRT는 model 분석을 통해 네트워크에 사용되는 모든 tensor들의 lifetime을 알 수 있기에, 최적화된 메모리 영역 크기 파악 및 사용 스케쥴링이 가능.
- Multi-Stream Execution : 여러 input에 대한 병렬처리가 가능함. 이것에 대한 자세한 설명은 찾지 못하였는데, multiple GPUs (or MIG 자동) 를 자동으로 사용가능하게 해주는 것이 아닐까 함.
- Time Fusion : Recurrent neural networks에 대한 최적화. 이것에 대해서도 정리된 설명은 찾지 못해, document를 읽어서 정리해야겠음.
TensorRT의 네트워크 최적화 방법 : Layer Fusion
2022.05.03 - [Deep Learning/jhDNN] - cuDNN Graph API (1) (Feat, Operator Fusion & TVM)
Layer fusion은 위 포스터에서도 한번 다룬 적 있는데, data reuse를 매우 높일 수 있는 최적화 방법 중 하나이다. 여러 layer (operator, kernel) 들을 하나의 layer로 합치는 기술로, 한 layer의 결과를 곧바로 다른 layer가 사용할 수 있도록 함으로서 off-chip memory 접근을 줄여 성능을 높인다.
Fig 3.는 layer fusion의 예시를 잘 보여주는 그림이다. Fig 3.에서 보듯, Conv2D, bias, activation layer를 하나로 합쳐서 하나의 layer로 만들 수 있다. Layer fusion이 없었다면 DRAM 읽기 -> con2D 연산 -> DRAM 쓰기 -> DRAM 읽기 -> bias 연산 -> DRAM 쓰기 -> DRAM 읽기 -> activation 연산 -> DRAM 쓰기의 순으로 진행되었겠지만, layer fusion을 통해 DRAM 읽기 -> con2D 연산 -> bias 연산 -> activation 연산 -> DRAM 쓰기만으로 연산 과정을 줄일 수 있다. 즉 DRAM에 접근할 필요 없이, conv2D의 데이터 결과를 그대로 bias에서 재사용(reuse)하고, bias의 결과를 그대로 activation에서 재사용한다.

TensorRT는 연속적인 연산 (conv2d->bias->relu) 들의 fusion 뿐만 아니라, 독립적인 연산 (conv2d, conv2d, conv2d) 들의 fusion 또한 지원한다. 이 경우 data reuse를 통한 성능 향상이 아니라, kernel launch 횟수 감소 및 충분한 개수의 thread 제공을 목표로 하는 것 같다. (개인적인 추측이다.)
예를 들어 GPU에 5000개의 cores가 있다고 하자. (context switching을 통한 memory latency hiding 등의 최적화를 위하여) 보통 5000개의 n배에 해당하는 threads가 존재하는 것이 좋다. 만약 이미지의 크기가 32*32일 경우, 하나의 1*1 conv2는 보통 32*32=1024개의 thread만을 생성할 것인데, 이렇게 된다면 GPU의 약 4천개의 cores가 아무일도 하지 않을 것이다. 따라서 여러개의 1*1 conv2d를 동시에 실행시켜 이러한 idle cores가 없도록 하는 것을 목표로 독립적인 연산들의 fusion도 지원하는 것 같다. (다시 말하지만 개인적인 추측이다.)
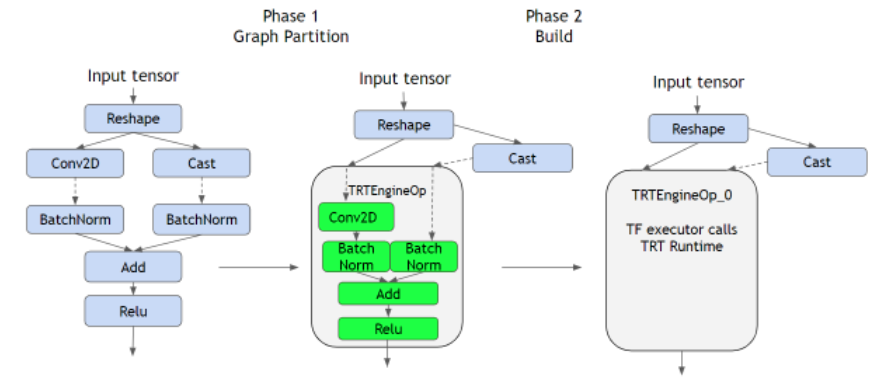
Fig 4.는 layer fusion의 좀 더 자세한 예시이다. 딥러닝 네트워크는 Fig 4.와 같이 graph 형태로 나타낼 수 있는데, graph의 node는 layer(operator)이고, edge는 데이터의 이동 방향을 나타낸다. TensorRT는 모든 layer에 대한 최적화를 지원하지 않는다. Fig 4.는 tensorflow로 만든 딥러닝 네트워크인데, cast layer, reshape layer는 tensorflow에서는 지원하지만 TensorRT에서는 지원하지 않는다.
TensorRT는 따라서 graph를 parsing하며 최적화 가능한 layer들로만 구성된 sub-graph들을 찾는다. 이렇게 찾은 sub-graph들에 대하여 layer fusion을 진행한다. 최종적으로 하나의 sub-graph가 하나의 최적화된 engine node가 되고, 전체 그래프는 최적화된 engine node + 최적화되지 않는 layer node로 구성된다. 이 방식을 통해 TensorRT는 지원하지 않는 layer를 포함한 딥러닝 네트워크에 대해서도 지원하는 layer들에 대해서만 최적화를 진행하도록 하여 flexibility를 극대화하였다. (어떠한 네트워크가 와도 어느정도 최적화가 가능하다.)
TensorRT의 네트워크 최적화 방법 : Reduced Precision
일반적으로 딥러닝 네트워크는 FP32 데이터 타입을 가진다. FP32 데이터타입은 ~10의 38승부터 10의 38승까지의 숫자를 나타낼 수 있을 뿐만 아니라, 소수점 밑으로도 높은 정확도로 표현할 수 있다. 따라서 FP32는 딥러닝 네트워크의 weights를 표현하기 좋은 데이터타입이다. 하지만 FP32 데이터 타입 연산을 FP16, INT8과 같은 표현 가능한 정확도가 낮은 데이터 타입 연산으로 대체하면 연산 성능 및 메모리 효율을 증가시킬 수 있다. FP32 데이터 타입 연산을 FP16 데이터 타입 연산으로 대체하는 것과 INT8 데이터 타입 연산으로 대체하는 것은 약간이 차이가 있다.
이전 포스터에서 FP16을 이용한 딥러닝 연산에 대하여 정리하였다. FP16의 경우 정확도는 낮지만 여전히 소수 표현이 가능하기에 FP32 연산을 FP16 연산으로 바꾸는 것은 INT8 연산으로 바꾸는 것보다 간단하다.
그에 비해 FP32 연산 -> INT8 연산으로 변경하는 것은 INT8이 정수만 표현가능하며 ~128 ~ 127까지의 숫자만 표현가능한 매우 낮은 정확도를 가지고 있기에 매우 복잡한 calibration 과정 등이 필요하다. 자세한 설명은 [5], [6]을 참고하여, 추후 다른 포스터로 정리해서 올려야겠다.

Fig 5.는 reduced precision을 통한 성능 향상을 보여준다. FP32 연산을 INT8 연산으로 바꿔 실행할 경우 매우 빠른 성능향상을 보여준다. 특히 FP16의 경우 specialized hardware인 Tensor core를 통해 더욱 향상된 speedup을 보여준다.
TensorRT Workflow

FIg 6.은 어떻게 TensorRT가 딥러닝 네트워크 최적화를 수행하는 지를 잘 보여준다. TensorRT는 크게 2가지 단계로 나뉘는데, step 1은 학습된 네트워크 모델을 분석하여 최적화하는 단계, step 2는 최적화된 모델을 실제 환경에서 실사용하는 단계이다.
TensorRT는 inference 과정을 최적화해주는 SDK로, Step 1에 앞서 이미 학습이 완료된 딥러닝 모델이 필요하다. 앞서 설명했듯 다른 딥러닝 프레임워크를 통해 학습된 딥러닝 모델을 TensorRT의 입력으로 하여 최적화를 진행한다. TensorRT는 딥러닝 네트워크를 분석하여 6가지 최적화를 진행한다. 이후 최적화된 결과를 저장(serialize, 직렬화)한다. 이 단계는 Ahead-of-Time에 진행되는 단계로, 딥러닝 배포 이전에 최적화(step 1)를 수행한 후 그 결과를 저장해둔다.
Step 2는 실제 딥러닝 네트워크가 배포되어 제품으로서 작동하는 단계이다. TensorRT는 Python 혹은 C++ API를 제공하여, python(C++)로 작성된 제품(프로그램)에서 TensorRT로 최적화된 모델을 호출하여 inference를 진행할 수 있다. 구체적으로 TensorRT runtime engine이 저장된 최적화된 딥러닝 네트워크를 load한다. 이후 딥러닝 추론 API가 호출될 시, 최적화된 딥러닝 네트워크를 이용하여 추론을 진행한다.
최적화 과정에서 딥러닝 네트워크에 대한 정보를 이용한 최적화 (layer fusion 등), 실제 배포되는 GPU 환경에 맞는 최적화 (kernel auto-tuning) 도 진행된다. 이러한 GPU 환경에 맞는 최적화는 프로그래머의 선택에 따라 step 1 또는 step 2에서 진행될 수 있다. step 1에서 진행될 경우 직접 타겟 GPU 시스템을 명시해주고 그 GPU에 대한 build (최적화)를 진행한다. 이 경우 step 1의 결과인 최적화된 모델은 해당 GPU 시스템에서만 사용될 수 있다. Step 2에서 타겟 GPU 시스템을 명시하고 build를 진행할 경우, build 시 추가적인 시간이 소모될 수 있다.
Reference
[1] https://blog.tensorflow.org/2021/01/leveraging-tensorflow-tensorrt-integration.html
[2] https://developer.nvidia.com/blog/deploying-deep-learning-nvidia-tensorrt/
[3] https://developer.nvidia.com/tensorrt
[4] Shashank Prasanna, DEEP LEARNING DEPLOYMENT WITH NVIDIA TENSORRT, NVIDIA
[5] Szymon Migacz, 8-bit Inference with TensorRT, NVIDIA, May 8, 2017
[6] Dheeraj Peri, Jhalak Patel, Josh Park, DEPLOYING QUANTIZATION-AWARE TRAINED NETWORKS USING TENSORRT, NVIDIA
'Deep Learning > Optimization (Algorithm)' 카테고리의 다른 글
| TensorRT (2) 설치 및 샘플 테스트 (Ubuntu 18.04 기준) (0) | 2022.07.08 |
|---|---|
| Compression - 4 : Quantization (2) Post Training Quantization 분석 (Calibration, TensorRT) (0) | 2022.06.16 |
| Compression - 3 : Quantization (1) 기본 아이디어 및 핵심 (0) | 2022.06.15 |
| Compression - 2 : PyTorch Pruning Tutorial 및 계산 속도가 빨라지지 않는 이유 (0) | 2022.04.29 |
| Compression - 1 : Overview (0) | 2022.03.29 |



