
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 반도체기초
- HA
- kubernetes
- Semiconductor
- FPGA
- jhVM
- 쿠버네티스
- CuDNN
- stl
- convolution
- 딥러닝
- jhDNN
- POD
- nvidia
- cloud
- deep_learning
- Compression
- DRAM
- 클라우드
- Qubit
- sycl
- CUDA
- flash_memory
- 양자역학의공준
- 반도체
- SpMM
- C++
- GPU
- quantum_computing
- dnn
- Today
- Total
Computing
Compression - 3 : Quantization (1) 기본 아이디어 및 핵심 본문
Compression - 3 : Quantization (1) 기본 아이디어 및 핵심
jhson989 2022. 6. 15. 21:49이전글
2022.03.29 - [Deep Learning/Optimization (Algorithm)] - Compression - 1 : Overview
2022.04.29 - [Deep Learning/Optimization (Algorithm)] - Compression - 2 : PyTorch Pruning Tutorial 및 계산 속도가 빨라지지 않는 이유
이전 포스터에서 딥러닝 네트워크 compression에 대한 개념 및 Pruning에 대하여 정리하였다. 이번 포스터에서는 network compression 방법 중 하나인 quantization에 대하여 정리하고자 한다.
Quantization의 개념 및 필요성
Quantization(양자화)이라는 단어는 컴퓨터공학 입문 정도의 강의에서 다들 배웠을 것이다. 아날로그 신호(연속적인 범위를 가지는 신호)를 이산적인 신호로 근사하는 과정[7]을 뜻하는데, 컴퓨터는 양자화를 통해 자연 내의 아날로그 신호(소리, 빛의 세기 등)를 0과 1의 데이터로 저장할 수 있게 되었다.
이러한 양자화의 개념을 딥러닝 네트워크 compression(압축)에 적용하는 연구가 활발히 진행되고 있다. 딥러닝 네트워크 양자화는 딥러닝 네트워크의 parameters와 feature map(or tensor)을 FP32 데이터 타입에서 INT8 (나아가 INT4, INT2, INT1) 데이터 타입으로 근사하고자 한다. 이를 통해 네트워크 크기 압축은 물론 연산 속도 향상을 꾀한다.

일반적으로 딥러닝 네트워크는 FP32 (32bit floating point) 데이터 타입으로 많이 구현을 한다. Fig 1.은 데이터 타입 별 표현 가능한 숫자의 범위 및 최소 숫자 크기를 나타낸다. FP32 데이터 타입은 ~10의 38승부터 10의 38승까지의 숫자를 표현할 수 있을 뿐만 아니라, 높은 정확도로 소수를 표현할 수 있다. 따라서 딥러닝 네트워크에서 사용되는 숫자(2.0123, -1.45, 0.0001 등)를 충분히 표현할 수 있을 정확도를 가진다.

Fig 2.는 FP32 데이터 타입 대비 INT8 데이터 타입을 사용할 경우 얻게 되는 에너지 및 반도체 공간 상의 이점을 보여준다. FP32 데이터타입은 32bit를 사용하여 데이터를 저장한다. 만약 딥러닝 네트워크에 사용되는 데이터타입을 FP32에서 INT8 타입으로 바꿀 수 있다면 사용 전력(Fig 2.의 Energy saving 항목) 및 필요한 chip 공간 크기(Fig 2.의 Area saving 항목)도 줄어들 것이다. 또한 일반적으로 integer 연산은 floating 연산에 비해 (매우) 빠르기에[3] 추론 속도 향상을 기대할 수 있을 것이다. 이러한 맥락에서 딥러닝 네트워크의 데이터(parameters, tensors, feature maps) 표현에 사용되는 FP32 데이터 타입를 INT8로 바꾸려는 quantization 연구가 진행되고 있다.
딥러닝 네트워크 양자화는 일반적으로 학습(training) 과정보다는 추론(inference) 과정의 최적화를 위해 사용된다. 따라서 이미 학습이 완료된 딥러닝 네트워크에 대하여 양자화를 진행하고, 그 결과로 양자화된 딥러닝 네트워크가 출력된다. 즉 양자화는 이미 학습이 완료된 네트워크에 대한 후처리 작업으로, 딥러닝 네트워크의 데이터(parameters, tensors, feature maps)를 calibration, fine-tuning 한다. 이렇게 양자화된 딥러닝 네트워크는 실제 제품(production) 레벨에서 사용된다.
딥러닝 네트워크를 낮은 정확도의 데이터타입으로 바꾸는 것은 필연적으로 네트워크 성능에 부작용이 있을 수 밖에 없다. 데이터의 표현 가능한 범위 및 정확도가 바뀌기에 네트워크의 parameters의 값이 조금씩은 변할 것이다. 따라서 네트워크의 추론 정확도도 어느 정도 달라질 수 있다. 딥러닝 네트워크 양자화는 추론 정확도의 하락을 최대한 방지하는 것을 목표로 연구되고 있다. 연구 방향은 크게 두 가지 방향 "Post Training Quantization(PTQ)"와 "Quantization Aware Training(QAT)"으로 진행[1]되고 있다.
Quantization 기본 아이디어

F를 FP32 데이터 타입 수, Q를 INT8 데이터 타입 수라고 하자. 임의의 F,Q 에 대하여 Eq 1.과 같이 F와 Q의 관계를 나타낼 수 있는 α, β를 찾을 수 있을 것이다. 이때 α, β를 각각 Scaling factor(FP32), bias(FP32)라고 한다. Eq 1.과 같은 방식으로 FP32 데이터 타입 F를 INT8 데이터으로 변환 할 수 있다. 예를 들어 α=0.01, β=0.0이라 한다면 F=0.1를 Q=10로 변환할 수 있을 것이다. TensorRT의 경우 quantization을 구현할 때 bias는 0으로 하고 α만을 이용한다.
딥러닝 네트워크의 모든 parameters, tensor에 대하여 α를 따로 저장한다면, 오히려 양자화 이전보다 이후에 더 많은 메모리를 사용하게 될것이다. (F 1개만을 저장하면 될 것을, Q, α 2개 저장해야 하기에) 따라서 일반적으로 딥러닝 네트워크의 한 layer 혹은 한 tensor마다 하나의 α 값을 공유한다. (구현에 따라서 달라질 수 있다. 극단적으로 한 딥러닝 네트워크에 하나의 α를 공유할 수도 있을 것이다. TensorRT의 경우 한 layer 혹은 한 tensor마다 하나의 α 값을 공유[2]한다.)

Fig 3.은 딥러닝 네트워크의 한 layer에 대한 parameters 양자화를 보여주는 그림으로, 그림 속 X 표시들은 parameters를 나타낸다. FP32(~max부터 max 사이의 값, 이때 max는 parameter들 중 가장 절대값이 큰 숫자)으로 나타낼 수 있는 값들을 INT8(-127부터 127)까지의 수로 나타내는 예시이다. 이때 α는 다음 Eq 2.로 구할 수 있다.
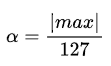
문제는 딥러닝 네트워크의 parameter의 max값은 매우 큰 수가 될 수도 있다는 것이다. 특히 max 값을 가지는 parameter가 outlier일 경우 더 큰 문제가 발생한다. 예를 들어 parameter들이 [1.0, 2.0, 3.0, 4.0, 5.0, 12700.0]일 때, α = 100이다. 따라서 양자화된 parameter들은 [0, 0, 0, 0, 0,127]이 될 것이다. 이 값들을 다시 dequantize할 시(=복원할시) [0.0, 0.0, 0.0, 0.0, 0.0, 12700.0]이 되는데, 많은 정보가 손실된 것을 확인할 수 있다. 이를 방지하기 위해 TensorRT는 Fig 4.와 같이 threshold를 두어 threshold보다 절대값이 큰 값은 127 혹은 -127로 saturate시킨다.

Threshold를 5로 설정할 경우, [1.0, 2.0, 3.0, 4.0, 5.0, 12700.0] -> [25, 50, 76, 101, 127, 127]이 된다. 양자화된 값을 다시 dequantize할 시, [0.98, 1.97, 2.99, 3.98, 5.0, 5.0]이 되는데, threshold가 없을 때에 비해 정보 손실이 덜함을 알 수 있다.
위 양자화 예제를 확장하여 matrix multiplication에도 도입할 수 있다. Fig 5.는 양자화를 이용한 matrix multiplication를 나타낸다.

Quantization 핵심 : α를 어떻게 선택할 것인가?
위의 예제에서 보듯, 어떠한 α를 선택하는 지에 따라 정보 손실 정도가 달라진다. 위 예제에서는 threshold를 두고, 매우 큰 값은 제거한 상태에서 max를 선택, 이 max를 이용하여 α를 구하였다. 이 예제에서는 어떤 threshold를 선택하는 지에 따라 정보 손실 정도가 많은 차이를 보였다.
앞서 설명하였듯이, 양자화는 "Post Training Quantization(PTQ)"와 "Quantization Aware Training(QAT)" 두 가지 방식으로 연구가 진행되고 있다. PTQ는 학습이 완료된 딥러닝 네트워크를 통계적으로 분석하여 α를 구하는 것이다. 위 예제는 PTQ에 해당한다. QAT는 학습을 통해 α를 구하는 것으로 학습이 완료된 딥러닝 네트워크에 quantization을 위한 layer를 추가한 후 다시 fine-tuning한다. 이러한 학습을 통해 적절한 α를 구한다. 이때 parameters의 weights 또한 업데이트할 수 도 있다.
두 가지 방식 모두 연구가 활발히 진행되고 있으며, 다음 포스터에서 두 방식에 대하여 좀 더 구체적으로 정리하고자 한다.
Reference
[1] Dheeraj Peri, Jhalak Patel, Josh Park, DEPLOYING QUANTIZATION-AWARE TRAINED NETWORKS USING TENSORRT, NDIVIA
[2] Szymon Migacz, 8-bit Inference with TensorRT, NVIDIA May 8, 2017
[3] https://intellabs.github.io/distiller/quantization.html [accessed June, 2022]
[4] Bei Yu, Efficient Computing of Deep Neural Networks, CSE Department, CUHK, Fall 2021 [lecture note]
[5] Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018
[6] I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio. Quantized neural networks: Training neural networks with low precision weights and activations. arXiv preprint arXiv:1609.07061, 2016
[7] https://ko.wikipedia.org/wiki/%EC%96%91%EC%9E%90%ED%99%94
'Deep Learning > Optimization (Algorithm)' 카테고리의 다른 글
| TensorRT (2) 설치 및 샘플 테스트 (Ubuntu 18.04 기준) (0) | 2022.07.08 |
|---|---|
| Compression - 4 : Quantization (2) Post Training Quantization 분석 (Calibration, TensorRT) (0) | 2022.06.16 |
| TensorRT (1) 개념, 최적화 방법, Workflow (Layer Fusion, Quantization 등) (0) | 2022.06.14 |
| Compression - 2 : PyTorch Pruning Tutorial 및 계산 속도가 빨라지지 않는 이유 (0) | 2022.04.29 |
| Compression - 1 : Overview (0) | 2022.03.29 |


